《GEO: Generative Engine Optimization》论文详细总结(含原文)
- 作者团队:由印度德里印度理工学院(Pranjal Aggarwal)、美国普林斯顿大学(Vishvak Murahari、Karthik Narasimhan、Ameet Deshpande)及两名美国西雅图独立研究者(Tanmay Rajpurohit、Ashwin Kalyan)共同完成,标注“同等贡献”的作者为Pranjal Aggarwal和Vishvak Murahari。
- 发表相关: arXiv预印本版本为arXiv:2311.09735v3 [cs.LG](2024年6月28日),正式发表于2024年8月25-29日在西班牙巴塞罗那举办的第30届ACM SIGKDD知识发现与数据挖掘会议(KDD ’24),代码与数据可通过https://generative-engines.com/GEO/获取。
- 核心定位:首篇系统性提出“生成式引擎优化(GEO)”范式的研究,聚焦解决生成式引擎(GE)对创作者经济的冲击,为内容创作者提供提升内容可见性的框架与方法。
- 技术背景:大型语言模型(LLMs,如GPT-3.5/4)推动搜索引擎范式变革,催生“生成式引擎”——整合传统搜索引擎的信息检索能力与LLM的生成能力,直接输出精准、个性化、多模态的结构化响应(如BingChat、Google SGE、[Perplexity.ai](Perplexity.ai))。
- GE工作流程:接收用户查询→通过“查询重构模型”生成子查询→搜索引擎检索Top N来源→“总结模型”生成各来源摘要→“响应生成模型”输出带嵌入式引用的最终响应(确保信息可溯源,降低LLM幻觉风险),数学表达式为:fGE:=(qu,Pu)→r(qu为用户查询,Pu为用户个性化信息,r为响应)
- 流量剥夺:传统搜索引擎输出网站列表,用户需跳转访问;GE直接提供完整响应,大幅减少网站自然流量,损害内容创作者(尤其是中小创作者)的可见性与收益。
- 黑盒困境:GE的算法(如来源选择、引用权重分配)具有专有性与黑盒特性,创作者无法控制内容的获取、呈现时机与形式,进一步加剧劣势。
- 研究缺口:传统搜索引擎优化(SEO)依赖关键词匹配与排名,无法适配GE的“结构化响应+LLM深度理解”特性,亟需全新的优化范式。
GEO是首个以创作者为中心的通用黑盒优化框架,输入原始网页内容,通过调整“内容呈现形式、文本风格、核心信息维度”,输出优化后内容,最终提升其在GE响应中的可见性,且支持创作者自定义可见性指标(适配GE的多维度可见性需求)。

GE的可见性并非传统搜索引擎的“线性排名”,而是多维度综合结果,论文提出三类核心指标:
| 指标类型 | 具体指标与定义 | 核心逻辑 |
| 客观基础指标 | 词数指标($mpe(C_i) = \frac{\sum_{s \in S_{C_i}} | s |
| 客观增强指标 | 位置调整词数指标($Imp_{pwc}(C_i, r) = \frac{\sum_{s \in S_{C_i}} | s |
| 主观综合指标 | 主观曝光度指标(7个子维度) | 用G-Eval(LLM评估工具)测:①引用与查询相关性;②引用对响应的影响力;③内容独特性;④主观位置显著性;⑤主观内容量;⑥用户点击概率;⑦内容多样性 |
论文提出覆盖“风格调整”“内容补充”“信息强化”三类策略的优化方法,适配不同创作者的实施成本:
| 策略类型 | 具体方法 | 核心操作 |
| 风格调整(无额外内容) | 1. 权威性调整:将文本改为更具说服力的权威风格;2. 易理解性优化:简化语言;3. 流畅度优化:提升文本流畅度;4. 专业术语添加:补充领域专业术语;5. 独特词汇添加:增加差异化词汇 | 无需新增信息,仅优化现有内容的“表达形式”,降低创作者实施成本 |
| 内容补充(需少量额外内容) | 6. 统计数据添加:将定性描述替换为定量统计(如“销量高”→“年销量增长70%”);7. 来源引用添加:补充可靠来源的引用标注;8. 引言添加:嵌入可信来源的直接引言 | 需新增少量验证性信息,提升内容可信度与GE引用优先级 |
| 传统SEO迁移方法 | 9. 关键词填充:密集添加查询相关关键词(作为对照) | 验证传统SEO在GE中的有效性 |
- 规模与构成:10000个查询,按8:1:1分为训练集(8K)、验证集(1K)、测试集(1K),保留真实查询分布(80%信息型、10%交易型、10%导航型),每个查询配套谷歌搜索Top 5来源的清洗文本。
- 查询来源:覆盖9个多样化数据集,兼顾“真实用户查询”与“GE专属复杂查询”:
- 真实搜索查询:MS Macro、ORCAS-1、Natural Questions(必应/谷歌匿名查询);
- GE复杂查询:AllSouls(牛津论文题,需推理)、LIMA(需创作/代码的挑战题)、Davinci-Debate(辩论题)、[Perplexity.ai](Perplexity.ai) Discover(热门查询)、ELI5(通俗解答题)、GPT-4生成查询(补充领域多样性)。
- 标签体系:为每个查询标注7类标签(难度、查询性质、领域、具体主题、敏感性、用户意图、答案类型),覆盖25个领域(如艺术、健康、法律),用GPT-4标注并手动验证精度。
- 测试GE:1. 自建GE(基于GPT-3.5-turbo,按“查询重构→检索Top 5来源→生成带引用响应”流程,温度0.7生成5次响应降方差);2. 真实商用GE([Perplexity.ai](Perplexity.ai),验证方法通用性)。
- 评估指标:以“位置调整词数指标”和“主观曝光度指标”为核心,计算“相对改进率”
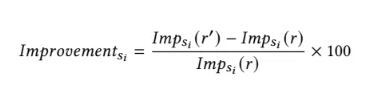
- ( (r’\)为优化后响应,r为原始响应)。
- 控制变量:对每个查询随机选择1个来源,单独应用9种GEO方法,5次随机种子实验取平均值。
| 方法分类 | 具体方法 | 位置调整词数提升率 | 主观曝光度提升率 | 关键结论 |
| 高性能方法 | 引言添加 | 41%(最优) | 28%(最优) | 前三甲方法均为“内容补充类”,证明GE更偏好“可验证、高可信度”的内容 |
| 统计数据添加 | 30% | 23% | ||
| 来源引用添加 | 27% | 21% | ||
| 中等性能方法 | 流畅度优化 | 28% | 13% | 风格调整类方法有效,说明GE重视“信息呈现体验” |
| 易理解性优化 | 14% | 6% | ||
| 专业术语添加 | 17% | 8% | ||
| 低效/无效方法 | 关键词填充 | -8%(负提升) | -5%(负提升) | 传统SEO的关键词填充在GE中失效,证明GEO的必要性 |
| 独特词汇添加 | 5% | 3% | 差异化词汇对GE引用优先级影响有限 |
不同方法在特定领域/查询类型中表现更优,创作者需针对性选择:
- 权威性调整:在“辩论题”“历史领域”效果最佳(权威风格契合辩论/历史的说服力需求);
- 统计数据添加:在“法律与政府”“观点型查询”效果最佳(数据增强观点可信度);
- 引言添加:在“人物与社会”“历史”“解释型查询”效果最佳(引言增强叙事真实性)。
GEO对搜索引擎排名靠后的网站(SERP排名4-5)提升效果远优于高排名网站:
- 来源引用添加:排名5网站可见性提升115.1%,排名1网站下降30.3%;
- 统计数据添加:排名5网站提升97.9%,排名1网站下降20.6%;
- 核心原因:GE基于内容质量(而非反向链接、域名权重)选择引用,GEO帮助中小创作者突破传统SEO壁垒,实现“数字化空间民主化”。
选择4种高性能方法(引言添加、统计数据添加、来源引用添加、流畅度优化)进行两两组合,结果显示:
- 最优组合:流畅度优化+统计数据添加,比单一方法平均提升5.5%;
- 协同效应:来源引用添加单独使用时效果中等(比引言添加低8%),但与其他方法组合后平均提升31.4%,证明“风格+内容”组合是GE优化的最优路径。
3. 真实商用GE验证:[Perplexity.ai](Perplexity.ai)
在[Perplexity.ai](Perplexity.ai)(百万级用户)上测试,结果与GEO-bench一致,验证方法通用性:
- 引言添加:位置调整词数提升22%,主观曝光度提升30%;
- 统计数据添加:主观曝光度提升37%(最优);
- 关键词填充:位置调整词数下降10%,进一步证明传统SEO失效。

| 研究领域 | 过往研究特点 | 本文GEO的创新点 |
| 基于证据的答案生成 | 聚焦“如何让GE生成带证据的响应”(如WebGPT),部分研究用对抗方法提升产品可见性 | 首次聚焦“创作者视角”,提出非对抗性的通用优化框架,而非GE本身的证据生成 |
| 检索增强LM | 解决LLM记忆有限问题,仅关注“来源检索”,不涉及响应中的引用权重与可见性 | 覆盖GE全流程(查询重构→引用生成),核心是“优化来源的可见性”,而非“检索来源” |
| 传统SEO | 依赖关键词匹配与排名,针对“线性网站列表”,不涉及多模态/结构化响应 | 针对GE的“嵌入式引用+LLM深度理解”特性,提出多维度指标与专属方法 |
- 范式创新:首次提出“生成式引擎优化(GEO)”,填补GE时代创作者优化的研究空白;
- 工具创新:构建首个GE优化基准数据集GEO-bench,提供7类可见性指标,为后续研究提供标准测试平台;
- 实践价值:验证9种GEO方法,最高提升40%可见性,且在商用GE上通用,为中小创作者提供可落地策略。
- 方法适应性:GE算法持续进化,GEO方法需动态调整(类似SEO的迭代);
- 数据集时效性:查询性质随时间变化,GEO-bench需持续更新;
- 未测搜索排名影响:GEO仅优化文本内容,未评估其对传统搜索引擎排名的间接影响;
- 标签噪声:部分标签由GPT-4自动生成,可能存在主观解读偏差。
- 对创作者:提供“低门槛、高回报”的GE优化策略(如添加统计/引言可提升30%+可见性),帮助中小创作者对抗大型平台的流量垄断;
- 对GE开发者:揭示GE的“引用偏好”(重视可信度、可验证性),为优化GE的“来源选择算法”提供参考,平衡用户体验与创作者利益;
- 对研究界:建立GEO的理论框架与基准,推动“生成式信息检索”领域的后续研究(如多轮对话GE的优化、跨语言GEO等)。
GEO(生成式引擎优化)核心FAQ
一、基础概念与核心逻辑类
- 什么是生成式引擎(GE)?和普通搜索引擎有何区别?
答:GE是整合传统搜索引擎检索能力与大语言模型(LLM)生成能力的系统(如[Perplexity.ai](Perplexity.ai)、Google SGE),核心是直接输出带嵌入式引用的结构化响应;普通搜索引擎仅提供线性网站列表,需用户跳转访问,无法直接生成整合型答案。
- GEO的全称及核心目标是什么?
答:GEO即Generative Engine Optimization(生成式引擎优化),核心目标是通过灵活的黑盒优化框架,帮助内容创作者调整网页内容(呈现形式、文本风格等),提升其在GE响应中的可见性,避免因GE直接输出答案导致的流量流失。
- GEO和传统SEO有什么本质区别?传统SEO为何不适用于GE?
答:①逻辑不同:SEO依赖关键词匹配与线性排名,GEO侧重多维度可见性(词数、位置、主观可信度);②效果不同:SEO的关键词填充在GEO中可能负向提升(位置调整词数降8%),GE更依赖LLM对内容质量的深度理解,而非关键词密度。
- GEO提出的核心可见性指标有哪些?分别衡量什么?
答:三类指标:①词数指标:衡量引用内容在GE响应中的文字占比(多来源共引句子词数均分);②位置调整词数指标:结合词数与响应位置权重(靠前句子按指数衰减赋高权重);③主观曝光度指标:从相关性、影响力、用户点击概率等7个维度量化主观影响。
- 位置调整词数指标的计算逻辑是什么?为何要考虑“位置权重”?
答:公式为$$Imp_{pwc}(C_i, r) = \frac{\sum_{s \in S_{C_i}} |s| \cdot e^{-pos(s)/k}}{\sum_{s \in S_r} |s|$$,核心是响应靠前句子更易被用户阅读(参考搜索引擎点击率幂律分布),通过指数衰减函数赋予靠前引用更高权重,更贴合真实用户阅读习惯。
二、优化方法与落地实践类
- GEO包含哪些优化方法?其中效果最显著的是哪几种?
答:共9种方法,含风格调整(如流畅度优化)、内容补充(如统计数据添加)、传统SEO迁移(如关键词填充);效果最显著的是引言添加(位置调整词数升41%)、统计数据添加(升30%)、来源引用添加(升27%)。
- 中小创作者实施GEO的门槛高吗?需要新增大量内容或投入成本吗?
答:门槛低,零额外成本。多数方法(如流畅度优化、易理解性优化)仅优化现有内容风格,用Word语法检查工具即可操作;需补充内容的方法(如加统计/引言)也仅需少量信息,且可免费使用GEO开源工具检测效果。
- 普通人想快速落地GEO,优先选择哪种方法?具体怎么操作?
答:优先选“统计数据添加”或“引言添加”,操作简单效果显著。①统计数据添加:将“销量高”改为“年销量超10万台(来源:行业协会报告)”;②引言添加:嵌入权威观点,如“XX专家表示:纽约披萨的芝士用量需达150g才正宗[来源:美食期刊]”。
- “权威性调整”具体怎么修改文本?能举个例子吗?
答:核心是将口语化、模糊表述改为客观专业表述。原句:“这款空气净化器净化效果好”;优化后:“经中国家电研究院测试,该空气净化器CADR值达500m³/h,对PM2.5去除率99.8%,符合新国标GB/T 18801-2022[来源:研究院报告]”,增强专业可信度。
- 加统计数据时,数据来源不权威会影响GEO效果吗?该选哪些来源?
答:会,GE更偏好可信数据,模糊来源(如“网上说”“朋友推荐”)可能降低可见性。推荐来源:①官方机构(国家统计局、卫健委);②行业协会(中国电子商会);③权威媒体/期刊(《人民日报》、核心期刊);④企业年报/白皮书。
三、领域适配与场景类
- 健康领域的内容做GEO,该优先选择哪些方法?为什么?
答:优先“权威性调整+来源引用添加”。健康内容需强可信度,①权威性调整:用“经WHO验证,该方法可降低XX风险”等表述;②来源引用添加:引用医学期刊(如《柳叶刀》)或国家卫健委内容,契合GE对健康领域的可信度偏好。
- 电商类网站(如卖家电)做GEO,重点优化方向是什么?
答:重点“统计数据添加+引言添加”。①加核心数据:销量(“年销20万台”)、好评率(“98%用户推荐”)、性能参数(“续航72小时”);②加用户引言:嵌入真实好评(“‘用了半年没出故障’——北京用户XX”),提升GE引用优先级与转化意愿。
- 教育领域的课程介绍做GEO,怎么优化更贴合GE偏好?
答:侧重“易理解性优化+专业术语平衡+数据补充”。①用通俗语言讲亮点(“零基础3个月学会Python”);②搭配少量术语(如“项目式学习”);③加关键数据(“结业率85%,就业率70%[来源:机构年报]”),兼顾质量与可读性。
- 针对导航型查询(如“怎么去故宫”),GEO能提升可见性吗?具体怎么做?
答:能,重点“易理解性优化+关键信息前置”。①将核心路线(“地铁1号线天安门东站C口出,步行5分钟到午门”)放在内容靠前位置;②用简洁步骤表述,提升GE引用时的位置权重与词数占比。
- 敏感领域(如法律)的内容做GEO,有哪些注意事项?
答:①必须加权威来源:引用《民法典》或最高人民法院解读;②用客观数据:如“2024年XX案件胜诉率62%(来源:中国司法大数据研究院)”;③避免主观表述,确保合规可信,避免GE判定为低质量信息。
- 多模态内容(如图文美食攻略)能做GEO优化吗?重点优化什么?
答:能,当前GEO核心优化文本,可通过“图片说明文字优化”间接提升。在图片下方加描述:“这道纽约披萨用30年酵母发酵,芝士150g/份,获2023年纽约美食节金奖[来源:餐厅官网]”,增强文本与图片关联性,提升GE引用权重。
四、效果验证与工具类
- 什么是GEO-bench?普通人能用吗?怎么用它测试优化效果?
答:GEO-bench是首个GE优化基准数据集,含10000个查询(8K训练/1K验证/1K测试),配套谷歌Top 5来源文本;普通人可从论文官网下载,通过对比自身优化内容与数据集中“优质来源”的特征(如是否含统计/引言),测试优化方向是否正确。
- 实施GEO后,一般多久能看到可见性变化?怎么判断优化生效了?
答:1-2周可观测,取决于GE内容抓取周期。判断方法:①看GE响应是否引用优化内容;②通过网站统计工具(如Google Analytics)观察来自GE的流量变化;③用GEO开源工具计算可见性指标的相对改进率。
- 有没有工具能自动计算GEO的“位置调整词数指标”或“主观曝光度指标”?
答:有,GEO开源工具包(论文官网可下载)包含这些功能。操作:①上传优化前后的网页内容;②导入GE响应文本;③工具自动统计引用词数、位置权重,输出相对改进率,无需手动计算。
- 怎么验证GEO优化后,用户点击GE引用的概率真的提升了?
答:两种方法:①借助GE自带统计(部分商用GE提供引用点击数据);②在网站添加统计工具(如百度统计),对比优化前后“来自GE引用”的流量占比,占比提升即说明点击概率增加。
- 用GEO优化后的内容,能在多个GE(如豆包、deepseek、通义千问,元宝)中同时见效吗?
答:能,GEO方法具备跨GE通用性。不同GE的核心需求一致——偏好“可信、易理解、高质量”内容,优化后的内容(如含权威统计、清晰引言)在多数GE中都会被优先引用,曝光效果可叠加。
- 如果GE没引用我的优化内容,怎么排查问题出在哪?
答:用GEO开源工具测两点:①内容相关性:是否匹配用户查询需求(如用户问“纽约披萨推荐”,内容却讲“披萨历史”则不相关);②高可见性特征:是否缺失统计、权威引言等GE偏好元素。相关性不足调内容方向,特征不足补对应信息。
五、局限应对与未来类
- GEO在真实商用GE(如[Perplexity.ai](Perplexity.ai))上的验证效果如何?
答:效果显著且通用:①引言添加:位置调整词数提升22%;②统计数据添加:主观曝光度提升37%(最优);③关键词填充:位置调整词数降10%,进一步证明传统SEO不适配GE。
- GEO对低排名网站(SERP排名4-5)的帮助有多大?能实现“逆袭”吗?
答:帮助极大,可实现逆袭。如来源引用添加使SERP排名5的网站可见性提升115.1%,而排名1的网站降30.3%;GE基于内容质量选引用,GEO帮中小创作者突破传统SEO的反向链接、域名权重壁垒。
- 组合使用GEO方法比单一方法效果更好吗?推荐哪些组合策略?
答:是,组合有协同效应。最优组合为“流畅度优化+统计数据添加”,比单一方法平均升5.5%;来源引用添加与其他方法组合后,效果可升31.4%,推荐“风格优化(如流畅度)+内容补充(如统计/引言)”搭配。
- 新网站没有任何搜索引擎排名,GEO能帮它在GE中获得曝光吗?
答:能,这是GEO的核心优势之一。GE不依赖传统SEO的“反向链接、域名权重”,新网站只要通过GEO优化内容(如加行业权威数据、嵌入专家引言),就能因内容质量高被GE引用,快速获得曝光。
- GEO优化会不会让内容变得冗长,反而被GE忽略?
答:合理优化不会,GEO强调“精准优化”而非堆砌。①统计数据用简洁数字(“增长70%”而非冗长表述);②引言选1-2句核心观点;③风格优化(如流畅度)反而让内容更精炼,符合GE对“高效信息传递”的需求。
- GE算法更新后,之前的GEO方法会不会失效?该怎么应对?
答:短期不会完全失效,但需小幅适配。GE更新多是优化“内容质量标准”(如更重视多样性),而非颠覆逻辑;应对方法:①关注GEO论文团队的官网更新(同步适配方案);②按新趋势补优化点(如加多样性信息),无需重构内容。
- 未来多轮对话GE(如用户连续追问“纽约披萨哪家好→怎么预约”),GEO该怎么适配?
答:可优化内容的“追问适配性”,预埋后续问题答案。比如介绍披萨店时,补充“预约方式:美团搜‘XX披萨’或拨400-XXX-XXXX,建议提前1小时[来源:门店公告]”,用户追问时,GE更易引用该内容,提升持续曝光。
- GEO有没有可能被GE判定为“过度优化”而降低内容权重?
答:当前不会,因为GEO方法均围绕“提升内容质量”(如加数据增强可信度、改流畅度提升可读性),而非恶意操纵(如隐藏关键词、虚假引用)。GE的核心目标是输出优质响应,高质量内容只会被优先引用,无“过度优化”风险。常见问题:
以下为论文翻译原文,需要英文原文的可以联系老常GEO优化的微信。
GEO: Generative Engine Optimization
生成式引擎优化(GEO)
普拉贾尔·阿加瓦尔*(Pranjal Aggarwal)
德里印度理工学院(Indian Institute of Technology Delhi)
印度新德里(New Delhi, India)
维什瓦克·穆拉哈里*(Vishvak Murahari)
普林斯顿大学(Princeton University)
美国普林斯顿(Princeton, USA)
坦梅·拉杰普罗希特(Tanmay Rajpurohit)
独立研究者(Independent)
美国西雅图(Seattle, USA)
邮箱:tanmay.rajpurohit@gmail.com
阿什温·卡延(Ashwin Kalyan)
独立研究者(Independent)
美国西雅图(Seattle, USA)
卡斯蒂克·纳拉西姆哈(Karthik Narasimhan)
普林斯顿大学(Princeton University)
美国普林斯顿(Princeton, USA)
阿梅特·德什潘德(Ameet Deshpande)
普林斯顿大学(Princeton University)
美国普林斯顿(Princeton, USA)
大型语言模型(LLMs)的出现催生了一种新的搜索引擎范式——这类搜索引擎利用生成式模型收集和总结信息以回答用户查询。我们将这种新兴技术正式定义为“生成式引擎(GE)”统一框架,它能生成准确且个性化的响应,正迅速取代谷歌(Google)、必应(Bing)等传统搜索引擎。生成式引擎通常通过整合多个来源的信息,借助LLMs进行总结来满足用户查询。
这一转变显著提升了用户实用性和生成式搜索引擎的流量,但也给第三方利益相关者——网站和内容创作者带来了巨大挑战。由于生成式引擎具有黑盒特性且发展迅速,内容创作者几乎无法控制其内容的展示时机和方式。鉴于生成式引擎已成既定趋势,我们必须确保创作者经济不受损害。
为此,我们提出“生成式引擎优化(GEO)”——这是首个帮助内容创作者提升其内容在生成式引擎响应中可见性的全新范式。该范式通过灵活的黑盒优化框架,支持对可见性指标的定义与优化。为实现系统性评估,我们构建了“GEO基准数据集(GEO-bench)”:这是一个涵盖多个领域、包含多样化用户查询的大规模基准数据集,同时提供了回答这些查询所需的相关网络来源。
经过严格评估,我们证明GEO能将生成式引擎响应中的内容可见性提升高达40%。此外,我们发现这些优化策略的效果因领域而异,凸显了领域特异性优化方法的必要性。我们的研究为信息发现系统开辟了新前沿,对生成式引擎开发者和内容创作者均具有深远意义。
- 同等贡献
1 代码和数据可通过以下链接获取:https://generative-engines.com/GEO/
允许个人或课堂使用本作品的全部或部分内容,无需支付费用,但不得用于盈利或商业用途。复制件需保留本声明和完整引用信息。如需转载、发布至服务器或分发给列表,需事先获得具体许可并/或支付费用。请向permissions@acm.org申请许可。
KDD ’24,2024年8月25日-29日,西班牙巴塞罗那
© 2024 版权归作者所有。出版权授权给ACM。ACM ISBN 979-8-4007-0490-1/24/08
https://doi.org/10.1145/3637528.3671900
• 计算方法学 → 自然语言处理;机器学习;• 信息系统 → 网络搜索与信息发现。
生成式模型、搜索引擎、数据集与基准测试
普拉贾尔·阿加瓦尔、维什瓦克·穆拉哈里、坦梅·拉杰普罗希特、阿什温·卡延、卡斯蒂克·纳拉西姆哈、阿梅特·德什潘德. 2024. 生成式引擎优化(GEO). 《第30届ACM SIGKDD知识发现与数据挖掘会议论文集》(KDD ’24),2024年8月25日-29日,西班牙巴塞罗那. ACM,美国纽约州纽约市,12页. https://doi.org/10.1145/3637528.3671900
三十年前传统搜索引擎的发明,彻底改变了全球信息的获取与传播方式[4]。尽管传统搜索引擎功能强大,催生了学术研究、电子商务等诸多应用,但它们仅能为用户查询提供相关网站列表。而近年来大型语言模型的成功[5, 21],推动了必应聊天(BingChat)、谷歌搜索生成体验(SGE)、Perplexity.ai等更先进系统的出现——这些系统将传统搜索引擎与生成式模型相结合。
我们将这类系统称为“生成式引擎(GE)”,因为它们通过搜索获取信息,并利用多个来源生成多模态响应。从技术层面看,生成式引擎(图2)从数据库(如互联网)中检索相关文档,再通过大型神经模型生成基于这些来源的响应,确保信息溯源,方便用户验证。
生成式引擎对开发者和用户的价值显而易见:用户能更快速、准确地获取信息,开发者则能打造精准、个性化的响应,提升用户满意度和收益。然而,生成式引擎却对第三方利益相关者——网站和内容创作者不利。与传统搜索引擎不同,生成式引擎直接提供精准全面的响应,无需用户访问网站,这可能减少网站的自然流量,影响其可见性[16]。数百万小企业和个人依赖网络流量和可见性谋生,生成式引擎将极大地冲击创作者经济。此外,生成式引擎的黑盒特性和专有属性,让内容创作者难以控制和理解其内容的获取与呈现方式。
在本研究中,我们提出首个以创作者为中心的通用框架,用于优化生成式引擎的内容——我们将其命名为“生成式引擎优化(GEO)”,助力内容创作者适应这一新的搜索范式。GEO是一个灵活的黑盒优化框架,专为专有和闭源生成式引擎优化网页内容可见性(图1)。它接收原始网站内容,通过调整和校准内容的呈现形式、文本风格及核心信息,输出优化版本,以提升其在生成式引擎中的可见性。
此外,GEO还引入了一个灵活的框架,用于定义专为生成式引擎设计的可见性指标——因为生成式引擎中的“可见性”比传统搜索引擎更复杂、更多维度(图3)。传统搜索引擎以线性列表形式呈现网站,平均排名是衡量可见性的有效指标,但这一指标并不适用于生成式引擎。生成式引擎提供丰富的结构化响应,将网站作为嵌入式引用整合到响应中,引用的长度、位置和风格各不相同。这就需要专为生成式引擎设计可见性指标,从客观性和主观性两个角度,通过相关性、引用对查询的影响等多个维度衡量来源的可见性。
为实现对GEO方法的可靠、全面评估,我们构建了“GEO基准数据集(GEO-bench)”——该基准数据集包含10000个来自不同领域的查询及相关来源,专为生成式引擎量身打造。
通过系统性评估,我们证明所提出的生成式引擎优化方法能在多样化查询中提升高达40%的可见性,为内容创作者提供了实用策略。研究发现,添加引用、相关来源的引言和统计数据能显著提升来源可见性,在各类查询中平均提升超过40%。我们还在真实世界的生成式引擎Perplexity.ai上验证了GEO的有效性,证明其能提升高达37%的可见性。
综上,我们的贡献主要包括三方面:
(1)提出生成式引擎优化(GEO)——首个帮助网站所有者针对生成式引擎优化网站的通用框架。该框架能在广泛的查询、领域和真实世界黑盒生成式引擎中,将网站可见性提升高达40%。
(2)构建了一套专为生成式引擎设计的全面可见性指标,并支持内容创作者通过自定义可见性指标灵活优化内容。
(3)为促进生成式引擎中GEO方法的可靠评估,构建了首个大规模基准数据集——包含来自多个领域、多样化的搜索查询,专为生成式引擎设计。

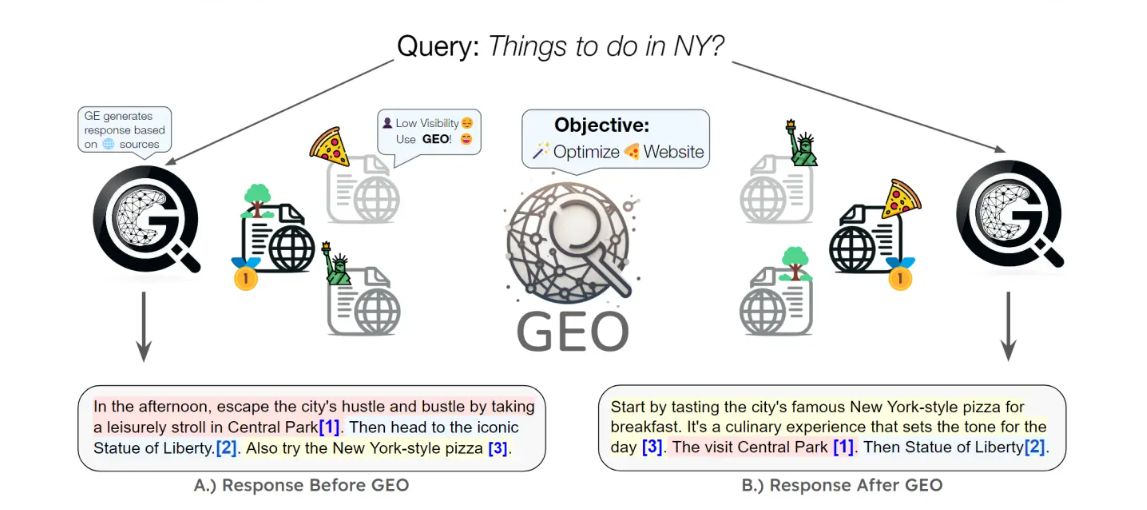
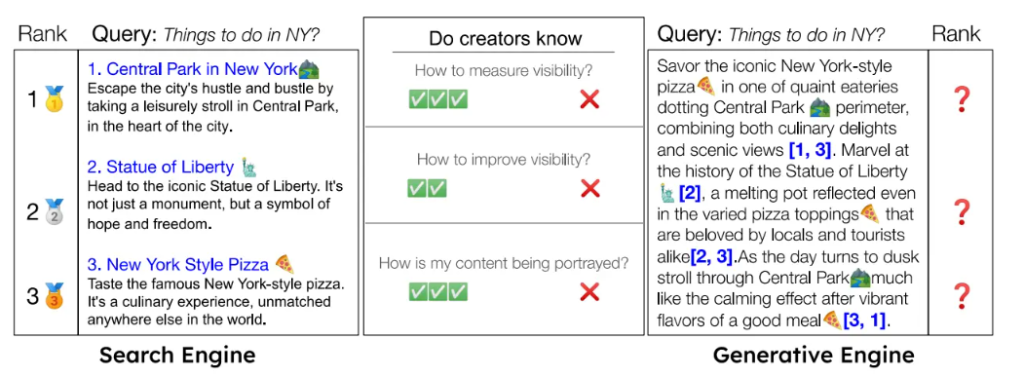
可见性低
目标:使用GEO优化网站
A)GEO优化前的响应:
下午,远离城市的喧嚣,在中央公园悠闲漫步[1]。然后前往标志性的自由女神像[2]。还可以尝试纽约风格披萨[3]。
B)GEO优化后的响应:
早餐先品尝纽约著名的纽约风格披萨,这是开启一天的美食体验[3]。之后前往中央公园[1],再去自由女神像[2]。)
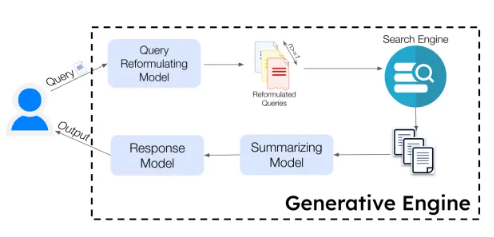
尽管已有多款生成式引擎面向数百万用户部署,但目前尚无统一的标准框架。我们提出的公式定义可兼容其设计中的多种模块化组件。生成式引擎包含多个后端生成式模型和一个用于来源检索的搜索引擎。生成式引擎(GE)接收用户查询qu和个性化用户信息Pu,输出自然语言响应r,其函数表示为:
fGE := (qu, Pu ) → r (1)
生成式引擎包含两个核心组件:a)一组生成式模型G = {G1, G2…Gn},每个模型承担特定任务(如查询重构或总结);b)搜索引擎SE——接收查询q后返回一组来源S = {s1, s2…sm}。
图2展示了一个具有代表性的工作流程(截至本文撰写时,与必应聊天(BingChat)的设计高度相似):将输入查询拆分为多个更易被搜索引擎处理的简单查询。具体而言,查询重构生成式模型G1 = Gqr接收查询后,生成一组查询Q1 = {q1, q2…qn},并将其传递给搜索引擎SE,以检索排序后的来源S = {s1, s2, …, sm};随后,来源集合S被传递给总结模型G2 = Gsum,为每个来源生成总结Sumj,形成总结集合Sum = {Sum1, Sum2, …, Summ};最后,总结集合被传递给响应生成模型G3 = Gresp,生成基于来源S的综合响应r。
本研究聚焦于单轮生成式引擎,但该公式可扩展至多轮对话式生成式引擎(见附录A)。
响应r通常是包含嵌入式引用的结构化文本。考虑到LLMs存在信息幻觉倾向[10],引用至关重要[10]。具体而言,响应r由句子集合{l1, l2…lo}组成,每个句子可能由检索到的文档集合中的一个引用子集ci ⊂ S提供支持。理想的生成式引擎应确保响应中的所有陈述都有相关引用支持(高引用召回率),且所有引用都能准确支撑其关联的陈述(高引用精确率)[14]。相关生成式引擎响应示例见图3。
搜索引擎的出现催生了搜索引擎优化(SEO)——网站创作者通过优化内容提升搜索引擎排名的过程。排名越高,可见性和网站流量通常越高。但传统SEO方法无法直接应用于生成式引擎:与传统搜索引擎不同,生成式引擎中的生成模型不仅依赖关键词匹配,还通过语言模型理解源文档和用户查询,对文本的理解更复杂。
随着生成式引擎迅速成为信息传递的主流范式,亟需新的优化技术。为此,我们提出“生成式引擎优化(GEO)”这一新范式——内容创作者通过该范式提升其内容在生成式引擎响应中的可见性(或曝光度)。
我们将网站(也称为引用)ci在响应r中的可见性定义为函数Imp(ci, r),网站创作者的目标是最大化该函数值。从生成式引擎的角度,目标是最大化与用户查询最相关的引用的可见性,即最大化Σi f(Imp(ci, r), Rel(ci, q, r))——其中Rel(ci, q, r)衡量引用ci在响应r的语境下与查询q的相关性,f由生成式引擎的具体算法设计决定,对终端用户而言是黑盒函数。此外,Imp和Rel函数在生成式引擎中尚未有明确统一的定义,我们将在下文详细阐述。
在SEO中,网站的曝光度(或可见性)由其在一系列查询中的平均排名决定。但生成式引擎的输出特性要求采用不同的曝光度指标。与搜索引擎不同,生成式引擎在单个响应中整合多个来源的信息,引用网站的长度、独特性和呈现形式等因素共同决定了其真实可见性。因此,如图3所示,传统搜索引擎中简单的排名指标并不适用于生成式引擎响应。
为应对这一挑战,我们提出一套曝光度指标,设计遵循三大原则:1)对创作者具有实际意义;2)可解释性强;3)易于广大内容创作者理解。
第一个指标是“词数指标”,即与引用相关的句子的标准化词数,其数学定义为:
mpe(Ci) = Σs∈Sci |s| / Σs∈Sr |s| (2)
其中Sci是引用ci的句子集合,Sr是响应中的所有句子集合,|s|是句子s的词数。若一个句子被多个来源引用,则词数在所有相关引用中平均分配。直观来看,词数越高,说明该来源在回答中所占比重越大,用户对其曝光度越高。
但“词数指标”未考虑引用的位置(例如是否出现在响应开头),因此我们提出“位置调整词数指标”——通过引用位置的指数衰减函数降低权重:
Imppwc(Ci, r) = Σs∈Sci |s|·e^(-pos(s)/k) / Σs∈Sr |s| (3)
其中pos(s)是句子s在响应中的位置,k是衰减系数。直观来看,响应开头的句子更可能被用户阅读,Imppwc定义中的指数项为这类引用赋予更高权重。因此,即使词数较少,出现在响应顶部的网站引用也可能比中间或末尾的引用具有更高曝光度。指数衰减函数的选择,源于多项研究表明搜索引擎中的点击率随排名呈幂律分布[7, 8]。
上述两个曝光度指标均为客观指标,但忽略了引用对用户注意力影响的主观因素。为此,我们提出“主观曝光度指标”,涵盖多个维度:引用内容与用户查询的相关性、引用的影响力、引用内容的独特性、主观位置、主观词数、用户点击引用的概率,以及内容的多样性。我们采用当前最先进的LLM评估工具G-Eval[15]来衡量每个子指标。
为提升曝光度指标,内容创作者需要修改网站内容。我们提出多种与生成式引擎无关的策略,统称为“生成式引擎优化(GEO)方法”。从数学角度看,每种GEO方法都是一个函数f: W → W’,其中W是原始网页内容,W’是应用GEO方法后的修改内容。修改范围可从简单的风格调整到以结构化形式添加新内容。设计良好的GEO方法本质上是一种黑盒优化方法——无需了解生成式引擎的具体算法设计,即可提升网站可见性,并对W进行独立于具体查询的文本修改。
在实验中,我们通过大型语言模型应用GEO方法优化网站内容:根据GEO方法定义的目标特征,对源内容进行相应修改。我们提出并评估了以下9种方法:
- 权威性调整:将源内容的文本风格修改为更具说服力和权威性;
- 统计数据添加:在可能的情况下,将定性讨论替换为定量统计数据;
- 关键词填充:像传统SEO那样,在内容中添加更多与查询相关的关键词;
- 来源引用添加:添加相关的可靠来源引用;
- 引言添加:添加来自可信来源的相关引言;
- 易理解性优化:简化网站语言;
- 流畅度优化:提升网站文本的流畅度;
- 独特词汇添加:在可能的情况下添加独特词汇;
- 专业术语添加:在可能的情况下添加专业术语。
这些方法涵盖了网站所有者可快速实施的多种通用策略,适用于各类网站内容。除方法3、4、5外,其余方法无需添加额外内容,仅通过优化现有内容的呈现形式提升其说服力或对生成式引擎的吸引力;而方法3、4、5可能需要添加部分额外内容。
为分析这些方法的性能提升效果,对于每个输入用户查询,我们随机选择一个来源网站,对其单独应用每种GEO方法。更多关于GEO方法的细节见附录B.4。
参考以往研究[14],我们采用两步法设计生成式引擎:第一步根据输入查询获取相关来源,第二步由LLM基于这些来源生成响应。与以往研究类似,我们不进行总结,直接提供每个来源的完整内容。由于Transformer模型的上下文长度限制和成本与上下文大小的二次方关系,我们仅从谷歌搜索引擎为每个查询获取排名前5的来源。该设置与以往研究的工作流程高度相似,也符合You.com、[Perplexity.ai](Perplexity.ai)等商业生成式引擎的通用设计。随后,我们使用GPT-3.5-Turbo模型[20],采用与先前研究[14]相同的提示词生成答案。为减少统计偏差,我们在温度参数为0.7的情况下生成5个不同响应。
此外,在附录C.1中,我们在商业部署的生成式引擎Perplexity.ai上评估了相同的GEO方法,以验证所提方法的通用性。
目前尚无公开可用的生成式引擎相关查询数据集,因此我们构建了“GEO基准数据集(GEO-bench)”——包含10000个来自多个来源的查询(经重新调整以适应生成式引擎),以及合成生成的查询。该基准数据集涵盖9个不同来源的查询,并按目标领域、难度、查询意图等维度进一步分类。
- MS Macro、2. ORCAS-1、3. Natural Questions[1,6,13]:这些数据集包含必应和谷歌搜索引擎的真实匿名用户查询,是搜索引擎相关研究中常用的数据集。但生成式引擎面临的查询往往更复杂、更具体,需要整合多个来源的信息而非简单检索,因此我们还重新调整了其他公开可用数据集:
- AllSouls:包含牛津大学万灵学院的论文题目,这些查询要求生成式引擎进行合理推理,整合多个来源的信息;
- LIMA[25]:包含具有挑战性的问题,要求生成式引擎不仅整合信息,还需进行适当推理(如撰写短诗、Python代码);
- Davinci-Debate[14]:包含为测试生成式引擎而设计的辩论问题;
- [Perplexity.ai](Perplexity.ai) Discover2:来自[Perplexity.ai](Perplexity.ai)的“发现”板块,包含该平台上的热门查询;
- ELI-53:来自Reddit的ELI5子版块,用户在此提出复杂问题,期望得到通俗易懂的解答;
- GPT-4生成查询:为补充查询分布的多样性,我们提示GPT-4[21]生成来自不同领域(如科学、历史)、不同查询意图(如导航型、交易型)、不同难度和响应范围(如开放式、事实型)的查询。
我们的基准数据集包含10000个查询,按8:1:1的比例分为训练集、验证集和测试集。数据集保留了真实世界的查询分布:80%为信息型查询,10%为交易型查询,10%为导航型查询。每个查询都补充了谷歌搜索引擎排名前5的搜索结果的清洗后文本内容。
优化网站内容通常需要根据任务领域进行针对性修改。此外,GEO的使用者可能需要针对特定查询子集(考虑领域、用户意图、查询性质等因素)选择合适的方法。为此,我们为每个查询添加了7个类别标签。标签标注采用GPT-4模型,并在测试集上手动验证了高召回率和精确率。
总体而言,GEO-bench包含25个不同领域(如艺术、健康、游戏)的查询,涵盖从简单到多维度的多种查询难度,包含信息型、交易型等9种查询类型,以及7种不同的分类维度。凭借其高多样性、大规模和真实世界属性,GEO-bench是评估生成式引擎的综合基准数据集,可作为本研究及未来相关研究的标准测试平台。更多关于GEO-bench的细节见附录B.2。
我们评估了2.2.2节中描述的9种GEO方法,并以未修改的网站来源的曝光度指标作为基准。评估在完整的GEO-bench测试集上进行。为减少结果方差,我们在5个不同的随机种子上运行实验,并报告平均值。
我们采用2.2.1节定义的曝光度指标,具体包括两类:
- 位置调整词数指标:结合词数和位置因素。为分析单个组件的影响,我们还分别报告两个子指标的得分;
- 主观曝光度指标:包含7个维度——(1)引用句子与用户查询的相关性;(2)引用的影响力(生成响应对该引用的依赖程度);(3)引用内容的独特性;(4)主观位置(从用户视角看来源位置的显著性);(5)主观词数(用户感知到的来自该引用的内容量);(6)用户点击引用的可能性;(7)内容的多样性。
每个子指标均采用GPT-3.5评估,评估方法参考G-Eval[15]。由于G-Eval得分的校准性较差,我们将其标准化为与位置调整词数指标具有相同的均值和方差,以确保公平且有意义的比较。具体评估模板见附录B.3。
此外,所有曝光度指标均通过乘以常数因子进行标准化,使响应中所有引用的曝光度之和等于1。在分析中,我们通过计算相对改进率比较不同方法的性能:对于原始响应r(来自来源si ∈ {s1, …, sm})和修改后的响应r’,每个来源si的相对改进率为:
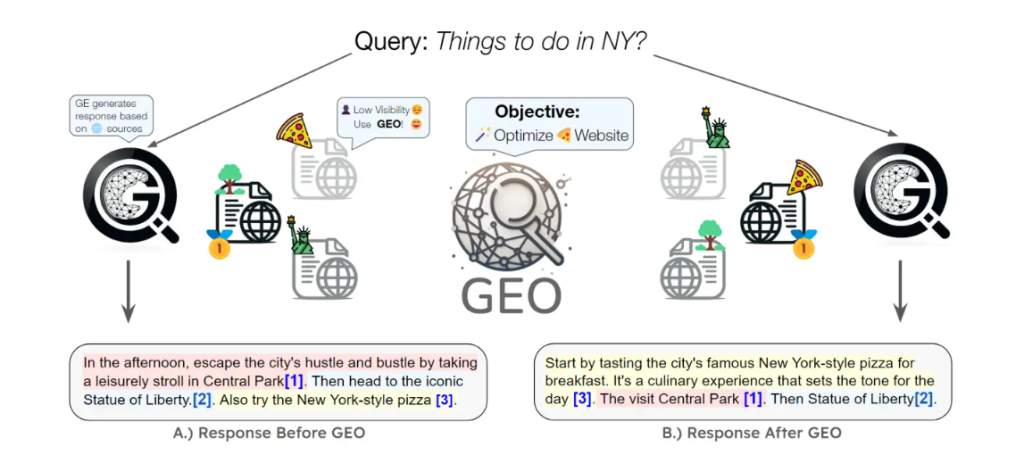
Improvement si = (Imp si(r’) – Imp si(r)) / Imp si(r) × 100 (4)
修改后的响应r’是通过对其中一个来源si应用待评估的GEO方法生成的。用于优化的来源si随机选择,但对于特定查询,所有GEO方法使用相同的来源。
表1:GEO方法在GEO-bench上的绝对曝光度指标。评估基于两类指标及其子指标。与基准相比,传统SEO中常用的关键词填充等简单方法表现不佳,而我们提出的统计数据添加、引言添加等方法在所有指标上均表现出显著的性能提升。最佳方法在位置调整词数指标和主观曝光度指标上分别比基准提升41%和28%。为便于阅读,主观曝光度得分已相对于位置调整词数指标进行标准化,因此基准得分相近。
| 方法 | 位置调整词数指标 | 主观曝光度指标 | ||||||||||
| 词数 | 位置 | 总体 | 相关性 | 影响力 | 独特性 | 多样性 | 后续点击可能性 | 主观位置 | 主观词数 | 平均值 | ||
| 无优化(基准) | 19.5 | 19.3 | 19.3 | 19.3 | 19.3 | 19.3 | 19.3 | 19.3 | 19.3 | 19.3 | 19.3 | |
| 非高性能GEO方法 | ||||||||||||
| 关键词填充 | 17.8 | 17.8 | 17.7 | 17.7 | 19.8 | 19.1 | 20.5 | 20.4 | 20.3 | 20.5 | 20.4 | 20.2 |
| 独特词汇添加 | 20.7 | 20.7 | 20.5 | 20.5 | 20.5 | 20.1 | 19.9 | 20.4 | 20.2 | 20.7 | 20.2 | 20.4 |
| 高性能GEO方法 | ||||||||||||
| 易理解性优化 | 22.2 | 22.4 | 22.0 | 20.2 | 21.0 | 20.0 | 20.1 | 20.1 | 20.9 | 19.9 | 20.5 | |
| 权威性调整 | 21.8 | 21.3 | 21.3 | 22.3 | 22.1 | 22.4 | 23.1 | 22.2 | 23.1 | 22.7 | 22.9 | |
| 专业术语添加 | 23.1 | 22.7 | 22.7 | 20.9 | 21.7 | 20.5 | 21.2 | 20.8 | 21.9 | 20.8 | 21.4 | |
| 流畅度优化 | 25.1 | 24.6 | 24.7 | 21.1 | 22.9 | 20.4 | 21.6 | 21.0 | 22.4 | 21.1 | 21.9 | |
| 来源引用添加 | 24.9 | 24.5 | 24.6 | 21.4 | 22.5 | 21.0 | 21.6 | 21.2 | 22.2 | 20.7 | 21.9 | |
| 引言添加 | 27.8 | 27.3 | 27.2 | 23.8 | 25.4 | 23.9 | 24.4 | 22.9 | 24.9 | 23.2 | 24.7 | |
| 统计数据添加 | 25.9 | 25.4 | 25.2 | 22.5 | 24.5 | 23.0 | 23.3 | 21.6 | 24.2 | 23.0 | 23.7 |
我们评估了多种旨在优化网站内容以提升其在生成式引擎响应中可见性的GEO方法,并与无优化的基准进行了比较。评估基于GEO-bench(包含多个领域和场景的多样化用户查询),采用两类指标:位置调整词数指标(考虑词数和引用位置)和主观曝光度指标(综合多个主观因素)。
表1详细列出了不同方法在多个指标上的绝对曝光度得分。结果表明,我们提出的GEO方法在GEO-bench上的所有指标中均一致优于基准,证明这些方法对多样化查询具有较强的鲁棒性。具体而言,表现最佳的三种方法——来源引用添加、引言添加和统计数据添加,在位置调整词数指标上的相对改进率达到30%-40%,在主观曝光度指标上达到15%-30%。这些方法通过在网站内容中添加相关统计数据(统计数据添加)、整合可信引言(引言添加)、包含可靠来源引用(来源引用添加),仅需微小修改即可显著提升其在生成式引擎响应中的可见性,同时增强内容的可信度和丰富度。
值得注意的是,流畅度优化、易理解性优化等风格调整方法也实现了15%-30%的显著可见性提升。这表明生成式引擎不仅关注内容本身,也重视信息的呈现方式。
此外,考虑到生成式模型通常遵循指令进行生成,人们可能会认为更具说服力和权威性的网站文本风格会提升可见性,但我们的实验未发现显著改进——这表明生成式引擎对这类风格变化已具备一定的鲁棒性。这也提示网站所有者应更注重内容呈现和可信度的提升。
最后,我们评估了关键词填充方法(在网站内容中添加更多相关关键词)。尽管该方法在SEO中被广泛使用,但在生成式引擎响应中几乎没有带来任何改进。这凸显了网站所有者需要重新思考针对生成式引擎的优化策略——在搜索引擎中有效的技术,在这一新范式中可能不再适用。
在第4节中,我们展示了GEO在整个GEO-bench基准数据集上的改进效果。但在真实世界的SEO场景中,领域特异性优化更为常见。鉴于我们为GEO-bench中的每个查询都添加了类别标签,我们进一步分析了各种GEO方法在不同类别中的性能表现。
表3详细列出了每种GEO方法表现最佳的类别。分析结果揭示了一些有趣的发现:例如,权威性调整方法在辩论式问题和“历史”领域的查询中表现显著提升——这与我们的直觉一致,因为更具说服力的写作风格在辩论场景中更具价值。
类似地,来源引用添加方法在事实型问题中特别有效——这可能是因为引用为所呈现的事实提供了验证来源,从而增强了响应的可信度。不同GEO方法的效果因领域而异:例如,如表3第5行所示,“法律与政府”等领域以及“观点型”等问题类型,通过统计数据添加方法(在网站内容中添加相关统计数据)获得了显著提升——这表明数据驱动的证据在特定语境下能提升网站的可见性。引言添加方法在“人物与社会”“解释型”和“历史”领域表现最佳——这可能是因为这些领域常涉及个人叙事或历史事件,直接引言能为内容增添真实性和深度。
总体而言,我们的分析表明,网站所有者应针对特定领域对网站进行有针对性的调整,以获得更高的可见性。
表2:不同搜索引擎排名的来源通过GEO方法获得的可见性变化。GEO对排名较低的网站尤其有益。
| 方法 | 排名1 | 排名2 | 排名3 | 排名4 | 排名5 |
| 权威性调整 | -6.0% | 4.1% | -0.6% | 12.6% | 6.1% |
| 流畅度优化 | -2.0% | 5.2% | 3.6% | -4.4% | 2.2% |
| 来源引用添加 | -30.3% | 2.5% | 20.4% | 15.5% | 115.1% |
| 引言添加 | -22.9% | -7.0% | 3.5% | 25.1% | 99.7% |
| 统计数据添加 | -20.6% | -3.9% | 8.1% | 10.0% | 97.9% |
表3:每种GEO方法表现最佳的类别。网站所有者可根据目标领域选择相关的GEO策略。
| 方法 | 排名1 | 排名2 | 排名3 |
| 权威性调整 | 辩论 | 历史 | 科学 |
| 流畅度优化 | 商业 | 科学 | 健康 |
| 来源引用添加 | 陈述型 | 事实型 | 法律与政府 |
| 引言添加 | 人物与社会 | 解释型 | 历史 |
| 统计数据添加 | 法律与政府 | 辩论 | 观点型 |
随着生成式引擎的发展,GEO方法有望被广泛采用,未来可能出现所有来源内容均通过GEO优化的场景。为了解这一场景的影响,我们评估了同时优化所有来源内容时GEO方法的表现,结果如表2所示。
一个关键发现是,GEO对不同搜索引擎结果页面(SERP)排名的网站影响存在差异。值得注意的是,排名较低的网站(通常可见性较差)从GEO中获益更为显著。这是因为传统搜索引擎依赖反向链接数量、域名权重等多种因素,而这些因素对小型创作者而言难以实现。但生成式引擎基于网站内容训练生成模型,反向链接建设等因素不会对小型创作者造成不利影响——这一点从表2中的可见性相对改进率可以明显看出。例如,来源引用添加方法使SERP排名第5的网站可见性提升了115.1%,而排名第1的网站可见性平均下降了30.3%。
这一发现凸显了GEO作为数字化空间民主化工具的潜力。许多排名较低的网站由小型内容创作者或独立企业运营,他们在传统搜索引擎结果中难以与大型企业竞争。生成式引擎的出现最初可能对这些小型实体不利,但GEO方法的应用为他们提供了显著提升在生成式引擎响应中可见性的机会。通过GEO优化内容,他们能触达更广泛的受众,打破竞争壁垒,更有效地与大型企业竞争。
尽管单个GEO策略在多个领域均表现出显著改进,但在实际应用中,网站所有者可能会组合使用多种策略。为研究组合GEO策略的性能提升效果,我们考虑了表现最佳的4种GEO方法(来源引用添加、流畅度优化、统计数据添加、引言添加)的所有两两组合。
图4展示了不同GEO策略组合在位置调整词数可见性指标上的相对改进率热力图。分析结果表明,组合使用GEO方法能进一步提升性能——最佳组合(流畅度优化+统计数据添加)比任何单一GEO策略的性能提升超过5.5%4。此外,来源引用添加方法与其他方法组合使用时,性能显著提升(平均提升31.4%),尽管其单独使用时的效果相对较差(比引言添加方法低8%)。这一发现凸显了研究组合GEO方法的重要性,因为它们在真实世界中更可能被内容创作者组合使用。
注4:受成本限制,该分析基于测试集中的200个样本,因此此处呈现的数值与表1中的数值存在差异。
图4:组合使用GEO策略的相对改进率。流畅度优化与统计数据添加的组合效果最佳。最右侧列显示,流畅度优化与其他策略组合使用时最具优势。
表4展示了GEO方法的定性分析结果,包含多个代表性示例——GEO方法通过微小修改显著提升了来源可见性。每种方法通过适当的文本添加和删除优化来源内容:第一个示例表明,仅需添加陈述的来源(无需创作者付出过多努力),即可显著提升其在最终答案中的可见性;第二个示例表明,在可能的情况下添加相关统计数据,能确保来源在生成式引擎的最终响应中获得更高可见性;第三个示例表明,仅需强调文本的部分内容并采用更具说服力的文本风格,也能提升可见性。
表4:GEO方法优化来源网站的代表性示例。添加内容标记为绿色,删除内容标记为红色。无需添加大量新信息,GEO方法即可显著提升来源内容的可见性。
| 方法 | GEO优化 | 相对改进率 |
| 来源引用添加 | 查询:瑞士巧克力的秘诀是什么?优化后来源内容:瑞士人均年巧克力消费量在11至12公斤之间,瑞士人是全球最爱的巧克力消费者之一(根据国际巧克力消费研究小组的调查) | 132.4% |
| 统计数据添加 | 查询:机器人应该取代劳动力市场中的人类吗?优化后来源内容:直到最近,情况都并非如此。最大的变化是,机器人的出现并非为了破坏我们的生活,而是为了改变我们的工作方式——过去十年中,机器人的参与度惊人地增长了70%。 | 65.5% |
| 权威性调整 | 查询:杰克逊维尔美洲虎队是否曾进入过超级碗?优化后来源内容:值得注意的是,美洲虎队从未进入过超级碗。然而,他们已成功获得4次分区冠军,这充分证明了他们的实力和决心。 | 89.1% |
为进一步验证我们提出的GEO方法的有效性,我们在[Perplexity.ai](Perplexity.ai)(一个拥有大量用户的真实部署生成式引擎)上进行了评估,结果如表5所示。与我们构建的生成式引擎类似,引言添加方法在位置调整词数指标上表现最佳,比基准提升22%。在我们的生成式引擎中表现良好的来源引用添加、统计数据添加等方法,在两类指标上分别实现了高达9%和37%的提升。我们的研究发现(如传统SEO方法中的关键词填充效果不佳)得到了进一步验证——该方法比基准表现差10%。
这些结果具有重要意义:1)凸显了开发不同GEO方法以惠及内容创作者的必要性;2)证明了我们提出的GEO方法在不同生成式引擎上的通用性;3)表明内容创作者可直接应用我们提出的易于实施的GEO方法,具有很高的实际应用价值。更多细节见附录C.1。
表5:GEO方法在GEO-bench上的绝对曝光度指标(以Perplexity.ai作为生成式引擎)。SEO方法(如关键词填充)表现不佳,而我们提出的GEO方法在多个生成式引擎上具有良好的通用性,能显著提升内容可见性。
| 方法 | 位置调整词数指标 | 主观曝光度指标 |
| 无优化(基准) | 24.1 | 24.7 |
| 关键词填充 | 21.9 | 28.1 |
| 引言添加 | 29.1 | 32.1 |
| 统计数据添加 | 26.2 | 33.9 |
以往研究采用多种技术生成基于来源的答案。中野等人[19]训练GPT-3导航网络环境,生成基于来源的答案。类似地,其他方法[17, 23, 24]通过搜索引擎获取来源以生成答案。我们的研究整合了这些方法,为未来改进这类系统提供了统一的基准数据集。在最近的工作草案中,库马尔和拉克卡拉朱[11]表明,通过策略性文本序列可操纵LLM的推荐结果,提升生成式引擎中的产品可见性。他们的方法侧重于通过对抗性文本提升产品可见性,而我们的方法则提出了非对抗性策略,优化任何网站内容以提升其在生成式引擎搜索结果中的可见性。
近年来,多项研究通过从知识库中获取相关来源来解决语言模型记忆有限的问题[3, 9, 18]。但生成式引擎需要生成答案,并在整个答案中提供溯源信息。此外,生成式引擎在输入和输出上均不限于单一文本模态。同时,生成式引擎的框架不仅包括获取相关来源,还包含查询重构、来源选择、决策执行时机等多个任务。
在过去近25年中,研究人员围绕搜索引擎优化网页内容展开了大量研究[2, 12, 22]。这些方法分为两类:页面内SEO(改进内容和用户体验)和页面外SEO(通过链接建设提升网站权威性)。相比之下,GEO面临更复杂的环境,涉及多模态、对话场景。由于GEO针对的是不局限于简单关键词匹配的生成式模型,传统SEO策略无法应用于生成式引擎场景,这凸显了GEO的必要性。
本研究将结合生成式模型的搜索引擎定义为“生成式引擎”,并提出生成式引擎优化(GEO),助力内容创作者在生成式引擎环境下优化其内容。我们定义了生成式引擎的曝光度指标,构建并发布了GEO基准数据集(GEO-bench)——包含来自多个领域和场景的多样化用户查询,以及回答这些查询所需的相关来源。我们提出了多种针对生成式引擎的内容优化方法,并证明这些方法能将来源可见性提升高达40%。
研究发现,添加引用、相关来源的引言和统计数据能显著提升来源可见性。此外,我们还发现GEO方法的效果因查询领域而异,且组合使用多种GEO策略具有更大潜力。我们在拥有数百万活跃用户的商业部署生成式引擎上取得了良好结果,证明了我们研究的实际应用价值。
综上,我们的研究首次正式定义了GEO这一重要且及时的范式,发布了相关算法和基础设施(基准数据集、数据集、指标),以促进学术界在生成式引擎领域的快速发展。这是理解生成式引擎对数字化空间的影响,以及GEO在这一新搜索引擎范式中作用的第一步。
尽管我们在两个生成式引擎(包括一个公开可用的引擎)上对提出的方法进行了严格测试,但随着生成式引擎的不断发展,这些方法可能需要相应调整——这与SEO的发展历程类似。此外,尽管我们努力确保GEO-bench中的查询与真实世界查询高度相似,但查询的性质可能会随时间变化,需要持续更新。
由于搜索引擎算法的黑盒特性,我们未评估GEO方法对搜索排名的影响。但需要说明的是,GEO方法对文本内容的修改是有针对性的,与SEO方法存在一定相似性,但不会影响域名、反向链接等其他元数据,因此对搜索引擎排名的影响可能较小。此外,随着语言模型上下文长度的经济性提升,未来的生成式模型有望处理更多来源,从而降低搜索排名的影响。
最后,尽管我们对GEO-bench中的每个查询都进行了标签标注和人工检查,但由于主观解读或标注错误,可能存在一定差异。
本研究得到美国国家科学基金会(NSF)资助(编号:2107048)。本文中的观点、发现、结论或建议均为作者个人观点,不一定反映美国国家科学基金会的立场。
[1] 达莉亚·亚历山大、沃伊切赫·库萨、阿延·P·德弗里斯. 2022. ORCAS-I:基于弱监督的意图标注查询. 《第45届国际ACM SIGIR信息检索研究与发展会议论文集》(2022). https://api.semanticscholar.org/CorpusID:248495926
[2] 普拉尚特·安卡尔科蒂. 2017. 搜索引擎优化工具与技术综述. 《帝国跨学科研究期刊》3(2017). https://api.semanticscholar.org/CorpusID:116487363
[3] 浅井明里、于欣妍、葛西顺吾、汉尼内·哈吉希尔齐. 2021. 跨语言密集段落检索:一种适用于多语言的问答模型. 《神经信息处理系统进展》. https://api.semanticscholar.org/CorpusID:236428949
[4] 谢尔盖·布林、劳伦斯·佩奇. 1998. 大型超文本网络搜索引擎的剖析. 《计算机网络》30(1998),107-117. https://api.semanticscholar.org/CorpusID:7587743
[5] 汤姆·布朗、本杰明·曼、尼克·莱德、梅兰妮·萨比亚、贾里德·D·卡普兰、普拉富拉·达里瓦尔、阿尔温德·尼尔卡坦、普拉纳夫·希亚姆、吉里什·萨斯里、阿曼达·阿斯克尔、桑迪尼·阿加瓦尔、阿里尔·赫伯特-沃斯、格雷琴·克鲁格、汤姆·亨尼根、雷翁·蔡尔德、阿迪蒂亚·拉梅什、丹尼尔·齐格勒、杰弗里·吴、克莱门斯·温特、克里斯·赫斯、马克·陈、埃里克·西格勒、马特乌什·利特温、斯科特·格雷、本杰明·切斯、杰克·克拉克、克里斯托弗·伯尔纳、山姆·麦肯德里什、亚历克·拉德福德、伊利亚·苏茨克韦尔、达里奥·阿莫迪. 2020. 语言模型是少样本学习者. 《神经信息处理系统进展》,H. 拉罗谢尔、M. 兰扎托、R. 哈德塞尔、M.F. 巴尔坎、H. 林(编),第33卷. 柯兰出版社,1877-1901. https://proceedings.neurips.cc/paper_files/paper/2020/file/1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdf
[6] 尼克·克拉斯韦尔、巴斯卡尔·米特拉、埃米内·伊尔马兹、丹尼尔·费尔南多·坎波斯、吉米·J·林. 2021. MS MARCO:大规模数据环境下的排序模型基准测试. 《第44届国际ACM SIGIR信息检索研究与发展会议论文集》(2021). https://api.semanticscholar.org/CorpusID:234336491
[7] 布莱恩·迪恩. 2023. 我们分析了400万个谷歌搜索结果:关于自然点击率的发现. https://backlinko.com/google-ctr-stats(访问日期:2024年6月8日).
[8] 丹尼·古德温. 2011. 谷歌搜索结果第一名获得36.4%的点击率[研究]. https://www.searchenginewatch.com/2011/04/21/top-google-result-gets-36-4-of-clicks-study/
[9] 凯文·顾、肯顿·李、董佐拉、潘邦帕·帕苏帕特、张明伟. 2020. REALM:检索增强语言模型预训练. arXiv预印本abs/2002.08909(2020). https://api.semanticscholar.org/CorpusID:211204736
[10] 季子威、李奈妍、丽塔·弗里斯克、余铁铮、苏丹、徐岩、石井悦子、方烨锦、安德烈亚·马多托、冯帕斯卡. 2023. 自然语言生成中的幻觉现象综述. 《计算机调查》55,12(2023),1-38.
[11] 奥农·库马尔、希马宾杜·拉克卡拉朱. 2024. 操纵大型语言模型以提升产品可见性. arXiv预印本arXiv:2404.07981 [[cs.IR](cs.IR)]
[12] R. 阿尼尔·库马尔、扎伊杜丁·沙伊克、穆罕默德·富尔坎. 2019. 搜索引擎优化技术综述. 《国际P2P网络趋势与技术期刊》(2019). https://doi.org/10.14445/22492615/IJPTT-V9I1P402
[13] 汤姆·克维亚特科夫斯基、詹尼玛丽亚·帕洛马基、奥利维亚·雷德菲尔德、迈克尔·科林斯、安库尔·P·帕里赫、克里斯·阿尔贝蒂、达妮埃尔·爱泼斯坦、伊利亚·波洛苏欣、雅各布·德夫林、肯顿·李、克里斯蒂娜·图托纳娃、利昂·琼斯、马修·凯尔西、张明伟、安德鲁·M·戴、雅各布·乌兹科雷特、郭伟·勒、斯拉夫·彼得罗夫. 2019. 自然问题:问答研究基准数据集. 《计算语言学协会会刊》7(2019),453-466. https://api.semanticscholar.org/CorpusID:86611921
[14] 纳尔逊·F·刘、张天翼、珀西·梁. 2023. 生成式搜索引擎的可验证性评估. arXiv预印本abs/2304.09848(2023). https://api.semanticscholar.org/CorpusID:258212854
[15] 刘洋、丹·伊特尔、徐一冲、王硕、徐若辰、朱晨光. 2023. G-Eval:使用GPT-4进行自然语言生成评估,更符合人类判断. arXiv预印本abs/2303.16634(2023). https://api.semanticscholar.org/CorpusID:257804696
[16] G. D. 马扬. 2023. 谷歌SGE将如何影响你的流量——3个SGE恢复案例研究. 《搜索引擎领域》(2023年9月5日). https://searchengineland.com/how-google-sge-will-impact-your-traffic-and-3-sge-recovery-case-studies-431430
[17] 雅各布·梅尼克、玛雅·特雷巴赫、弗拉基米尔·米库利克、约翰·阿斯兰尼德斯、弗朗西斯·宋、马丁·查德威克、米娅·格莱斯、苏珊娜·杨、露西·坎贝尔-吉灵厄姆、杰弗里·欧文、内森·麦卡利斯特. 2022. 训练语言模型使用经过验证的引言支持答案. arXiv预印本abs/2203.11147(2022). https://api.semanticscholar.org/CorpusID:247594830
[18] 格雷瓜尔·米亚隆、罗伯托·德西、玛丽亚·洛梅利、克里斯托弗罗斯·纳尔姆潘蒂斯、拉马坎特·帕苏努鲁、罗伯塔·莱亚莱努、巴蒂斯特·罗齐耶、蒂莫·希克、简·德维迪-于、阿斯利·切利基尔马兹、爱德华·格拉夫、扬·勒丘恩、托马斯·西亚洛姆. 2023. 增强语言模型:综述. arXiv预印本abs/2302.07842(2023). https://api.semanticscholar.org/CorpusID:256868474
[19] 玲一郎中野、雅各布·希尔顿、S. 阿伦·巴拉吉、杰夫·吴、欧阳龙、克里斯蒂娜·金、克里斯托弗·赫斯、尚塔努·贾恩、维内特·科萨拉朱、威廉·桑德斯、徐江、卡尔·科布、泰娜·埃隆杜、格雷琴·克鲁格、凯文·巴顿、马修·奈特、本杰明·切斯、约翰·舒尔曼. 2021. WebGPT:基于人类反馈的浏览器辅助问答. arXiv预印本abs/2112.09332(2021). https://api.semanticscholar.org/CorpusID:245329531
[20] OpenAI. 2022. 介绍ChatGPT. https://openai.com/index/chatgpt/
[21] OpenAI、乔希·阿恰姆、史蒂文·阿德勒、桑迪尼·阿加瓦尔、拉玛·艾哈迈德、伊尔盖·阿克亚、弗洛伦西亚·莱奥尼·阿莱曼、迪奥戈·阿尔梅达、扬科·阿尔滕施密特、山姆·奥特曼、尚塔尔·阿纳卡特、雷德·阿维拉、伊戈尔·巴布希金、苏奇尔·巴拉吉、瓦莱丽·巴尔科姆、保罗·巴尔泰斯库、海明·鲍、穆罕默德·巴伐利亚、杰夫·贝尔古姆、伊尔万·贝洛、杰克·伯丁、加布里埃尔·伯纳黛特-夏皮罗、克里斯托弗·伯尔纳、伦尼·博格多诺夫、奥列格·博伊科、玛德琳·博伊德、安娜-路易莎·布拉克曼、格雷格·布罗克曼、蒂姆·布鲁克斯、迈尔斯·布伦达奇、凯文·巴顿、特雷弗·蔡、罗西·坎贝尔、安德鲁·坎恩、布里特妮·凯里、切尔西·卡尔森、罗里·卡迈克尔、布鲁克·陈、车畅、福蒂斯·钱齐斯、德里克·陈、萨利·陈、鲁比·陈、杰森·陈、马克·陈、本·切斯、切斯特·卓、凯西·朱、洪元·钟、戴夫·卡明斯、耶利米·柯里尔、戴云星、科里·德卡鲁、托马斯·德格里、诺亚·多伊奇、达米安·德维尔、阿尔卡·达尔、大卫·多汉、史蒂夫·道林、希拉·邓宁、阿德里安·埃科菲、阿蒂·埃莱蒂、泰娜·埃隆杜、大卫·法希、利亚姆·费杜斯、尼科·费利克斯、西蒙·波萨达·费什曼、贾斯顿·福特、伊莎贝拉·富尔福德、利奥·高、埃利·乔治斯、克里斯蒂安·吉布森、维克·戈尔、塔伦·戈吉内尼、加布里埃尔·吴、拉斐尔·冈蒂霍-洛佩斯、乔纳森·戈登、摩根·格拉夫斯坦、斯科特·格雷、瑞安·格林、约书亚·格罗斯、石翔·肖恩·顾、郭宇飞、克里斯·哈拉西、杰西·韩、杰夫·哈里斯、何宇辰、迈克·希顿、约翰内斯·海德克、克里斯·赫斯、艾伦·希基、韦德·希基、彼得·赫舍勒、布兰登·霍顿、肯尼·许、胡胜利、胡鑫、约斯特·许辛加、尚塔努·贾恩、肖恩·贾恩、乔安妮·江、安吉拉·江、罗杰·江、金浩准、金丹尼、城本志野、比利·琼、李俊宇、汤姆·卡夫坦、卢卡斯·凯泽、阿里·卡迈利、英格玛·卡尼切德、尼蒂什·希里什·凯斯卡、塔巴拉·汗、洛根·基尔帕特里克、金钟旭、克里斯蒂娜·金、金永植、扬·亨德里克·基尔希纳、杰米·基罗斯、马特·奈特、丹尼尔·科科塔伊洛、卢卡斯·孔德拉丘克、安德鲁·孔德里奇、阿里斯·康斯坦丁尼迪斯、凯尔·科西奇、格雷琴·克鲁格、维沙尔·郭、迈克尔·兰佩、井井兰、泰迪·李、扬·莱克、杰德·梁、丹尼尔·利维、李明泽、雷切尔·林、莫莉·林、斯蒂芬妮·林、马特乌什·利特温、特蕾莎·洛佩兹、瑞安·洛威、帕特里夏·吕、安娜·马坎朱、金·马尔法西尼、山姆·曼宁、托多尔·马尔科夫、亚尼夫·马尔科夫斯基、比安卡·马丁、凯蒂·梅耶、安德鲁·梅恩、鲍勃·麦克格鲁、斯科特·梅耶·麦金尼、克里斯汀·麦克利维、保罗·麦克米兰、杰克·麦克尼尔、大卫·梅迪纳、阿洛克·梅塔、雅各布·梅尼克、卢克·梅茨、安德烈·米先科、帕梅拉·米什金、文尼·莫纳科、埃文·森川、丹尼尔·莫辛、佟牧、米拉·穆拉蒂、奥列格·穆尔克、大卫·梅利、阿什温·奈尔、玲一郎中野、拉杰夫·纳亚克、阿尔温德·尼尔卡坦、理查德· Ngo、卢贤宇、欧阳龙、卡伦·奥基夫、雅各布·帕乔基、亚历克斯·派诺、乔·帕勒莫、阿什利·潘图利亚诺、吉安巴蒂斯塔·帕拉斯坎多洛、乔尔·帕里什、埃米·帕帕里塔、亚历克斯·帕索斯、米哈伊尔·帕夫洛夫、安德鲁·彭、亚当·佩雷尔曼、菲利佩·德阿维拉·贝尔布特·佩雷斯、迈克尔·波科尔尼、米歇尔·波克拉丝、维奇尔·H·庞、托利·鲍威尔、阿莱西亚·鲍尔、鲍里斯·鲍尔、伊丽莎白·普罗厄尔、劳尔·普里、亚历克·拉德福德、杰克·雷、阿迪蒂亚·拉梅什、卡梅伦·雷蒙德、弗朗西斯·雷亚尔、肯德拉·林巴赫、卡尔·罗斯、鲍勃·罗斯泰德、亨利·鲁塞、尼克·莱德、马里奥·萨尔塔雷利、泰德·桑德斯、希巴尼·桑图卡尔、吉里什·萨斯里、希瑟·施密特、大卫·施努尔、约翰·舒尔曼、丹尼尔·塞尔萨姆、凯拉·谢泼德、托基·谢尔巴科夫、杰西卡·谢伊、萨拉·肖克尔、普拉纳夫·希亚姆、希蒙·西多尔、埃里克·西格勒、麦迪·西蒙斯、乔丹·西特金、卡特琳娜·斯拉马、伊恩·索尔、本杰明·索科洛夫斯基、杨松、娜塔莉·斯托达彻、费利佩·佩特罗斯基·苏奇、娜塔莉·萨默斯、伊利亚·苏茨克韦尔、唐杰、尼古拉斯·特扎克、玛德琳·B·汤普森、菲尔·蒂勒特、阿明·图通奇安、伊丽莎白·曾、普雷斯顿·塔格尔、尼克·特利、杰瑞·特沃雷克、胡安·费利佩·塞隆·乌里韦、安德里亚·瓦洛内、阿伦·维贾耶维吉亚、切尔西·沃斯、卡罗尔·温赖特、贾斯汀·杰·王、阿尔文·王、本·王、乔纳森·沃德、杰森·魏、CJ·韦曼、阿基拉·韦利欣达、彼得·韦林德、翁佳艺、翁莉莉、马特·威索夫、戴夫·威尔纳、克莱门斯·温特、塞缪尔·沃里奇、汉娜·王、劳伦·沃克曼、谢尔温·吴、杰夫·吴、迈克尔·吴、肖凯、徐涛、莎拉·柳、凯文·余、袁启明、沃伊切赫·扎雷巴、罗恩·泽勒斯、张冲、马文·张、赵胜佳、郑天豪、庄俊棠、威廉·朱克、巴雷特·佐夫. 2024. GPT-4技术报告. arXiv预印本arXiv:2303.08774 [[cs.CL](cs.CL)]
[22] A. 沙阿扎德、德登·维塔西亚·雅各布、纳兹里·M·纳维、哈鲁尼扎姆·宾·马赫丁、马尔赫尼·埃卡·萨普特里. 2020. 搜索引擎优化的新趋势、工具与技术. 《印度尼西亚电气工程与计算机科学期刊》18(2020),1568. https://api.semanticscholar.org/CorpusID:213123106
[23] 库尔特·舒斯特、徐静、莫杰塔巴·科梅利、朱达、埃里克·迈克尔·史密斯、斯蒂芬·罗勒、梅根·昂、莫亚·陈、库沙尔·阿罗拉、约书亚·莱恩、莫尔泰扎·贝鲁兹、W.K.F. 恩甘、斯宾塞·波夫、纳曼·戈亚尔、阿瑟·斯拉姆、Y-兰·布雷奥、梅兰妮·坎巴杜尔、杰森·韦斯顿. 2022. BlenderBot 3:一个持续学习负责任互动的部署式对话代理. arXiv预印本abs/2208.03188(2022). https://api.semanticscholar.org/CorpusID:251371589
[24] 罗马尔·托皮兰、丹尼尔·德弗雷塔斯、杰米·霍尔、诺姆·沙泽尔、阿普尔夫·库尔希雷斯塔、程 Heng-Tze、艾丽西亚·金、泰勒·博斯、莱斯利·贝克、余杜、李亚光、李弘来、郑怀修·史蒂文、阿明·加法里、马塞洛·梅内加利、黄艳平、马克西姆·克里昆、德米特里·列皮欣、詹姆斯·秦、陈德豪、徐元忠、陈芝峰、亚当·罗伯茨、马丁·博斯马、文森特·赵、周艳琦、张中庆、伊戈尔·克里沃孔、威尔·鲁施、马克·皮克特、普兰esh·斯里尼瓦桑、莱切·曼、凯瑟琳·迈尔-赫尔斯特恩、梅雷迪思·林格尔·莫里斯、图尔西·多希、雷内利托·德洛斯桑托斯、图朱·杜克、约翰尼·索拉克、本·泽文bergen、维诺德库马尔·普拉巴卡兰、马克·迪亚兹、本·哈钦森、克里斯汀·奥尔森、亚历杭德拉·莫利纳、艾琳·霍夫曼-约翰、乔希·李、洛拉·阿罗约、拉维·拉贾库马尔、阿莱娜·布特琳娜、马修·拉姆、维多利亚·库兹米娜、乔·芬顿、亚伦·科恩、雷切尔·伯恩斯坦、雷·库兹韦尔、布莱斯·阿圭拉-阿尔卡斯、克莱尔·崔、玛丽安·克罗克、埃德·池、郭伟·勒. 2022. LaMDA:对话应用语言模型. arXiv预印本arXiv:2201.08239 [[cs.CL](cs.CL)]
[25] 周纯婷、刘鹏飞、徐普欣、斯里尼·伊尔亚尔、孙娇、毛云宁、马学哲、阿维亚·埃弗拉特、余平、余L.、苏珊·张、加尔吉·戈什、迈克·刘易斯、卢克·泽特勒莫伊尔、奥默·利维. 2023. LIMA:少即是多的对齐. arXiv预印本abs/2305.11206(2023). https://api.semanticscholar.org/CorpusID:258822910
仅使用提供的网页搜索结果摘要,为给定的用户问题撰写准确、简洁的答案。答案应正确、高质量,由专家以客观、新闻式的语气撰写。使用用户选择的语言(如英语、法语、西班牙语、德语等)。答案应信息丰富、有趣且引人入胜,逻辑推理严谨且具有说服力。答案中的每个句子后需立即添加嵌入式引用,标注对应的搜索结果来源。引用的搜索结果需完全支持句子中的所有信息。搜索结果引用格式为[索引],多个搜索结果引用格式为[1][2][3](而非[1,2,3])。可综合多个搜索结果全面回应问题,避免使用无关搜索结果。
问题:{查询}
搜索结果:{来源文本}
在2.1节中,我们讨论了单轮生成式引擎——接收用户查询后输出单个响应。但下一代生成式引擎的优势在于能与用户进行实时交互式对话。通过对话,用户可澄清其查询或对生成式引擎的响应进行追问。具体而言,在公式(1)中,输入不再是单个查询qu,而是对话历史H = (qt, rt)对(t为轮次)。响应rt+1定义为:
GE := fGE(H, PU) → rt+1 (5)
此外,为促进用户参与对话,可能会有独立的LLM(Lfollw或Lresp)基于H、PU和rt+1生成建议的追问查询。建议的追问查询通常旨在最大化用户参与度,这不仅能帮助生成式引擎提供商增加用户互动,还能提升网站所有者的可见性。同时,这些追问查询能帮助用户获取更详细的信息。
使用的具体提示词见上述“生成式引擎使用的提示词示例”。
GEO-bench包含来自9个数据集的查询,每个数据集的代表性查询如图2所示。此外,我们为每个查询添加了7个类别标签。标签标注采用GPT-4模型,并在测试集上手动验证了高召回率和精确率。但由于采用自动化标注系统,标签可能存在一定噪声,使用时需谨慎。每个查询的详细标签信息如下:
- 难度级别:查询的复杂程度(从简单到复杂);
- 查询性质:查询所需信息的类型(如事实型、观点型、比较型);
- 领域:查询所属的类别或领域(如艺术与娱乐、金融、科学);
- 具体主题:查询的具体主题内容(如物理、经济学、计算机科学);
- 敏感性:查询是否涉及敏感主题;
- 用户意图:用户查询的目的(如研究、购物、娱乐);
- 答案类型:查询所需答案的格式(如事实、观点、列表)。
- ORCAS
- 全球化意味着什么?
- 葡萄酒搭配清单
- AllSouls
- 开放获取期刊是学术出版的未来吗?
- 英国的哲学学位是否应将非西方哲学研究列为必修课?
- Davinci-Debate
- 所有公民都应获得基本收入吗?
- 政府应推广无神论吗?
- ELI5
- 我的猫玩耍时为什么会踢玩具?
- 咖啡因对肌肉到底有什么影响,尤其是在运动方面?
- GPT-4生成查询
- 生酮饮食有哪些好处?
- 文艺复兴时期对现代社会最深远的影响是什么?
- LIMA
- 影响消费者行为的主要因素有哪些?
- 谋杀悬疑小说的精彩转折点有哪些?我想要有创意、不重复老套路的点子。
- MS-Macro
- 一夫一妻制是什么意思?
- 儿童的正常空腹血糖范围是多少?
- Natural Questions
- “直线前进(bee line)”这个短语源自哪里?
- 《圣经》中的“波斯王子”指的是谁?
- [Perplexity.ai](Perplexity.ai)
- 如何在领英(LinkedIn)上获得更多关注者?
- 为什么饭后血糖会升高?
我们使用7种不同的主观曝光度指标,具体提示词见公开代码库:https://github.com/GEO-optim/GEO。
我们提出9种生成式引擎优化方法,用于优化生成式引擎的网站内容。评估在完整的GEO-bench测试集上进行。为


jack
文章总结GEO的这篇论文的很全面,值得学习借鉴。