
大模型生成与推荐答案的核心原理
我们将彻底解构大模型从一堆无序的字节到能与您对话并提供推荐的完整生命周期。请放心,我会尽可能地将每个环节讲清楚。
我们可以将这个过程分为三个宏大的阶段:
- 预训练 (Pre-training): 从混沌中构建一个通用的、包含世界知识的“大脑”。
- 对齐 (Alignment): 教会这个“大脑”如何像人类一样思考、对话并遵守规则。
- 推理 (Inference): 当您提问时,“大脑”如何实时地思考并生成一个具体的答案。

第一阶段:预训练 (Pre-training) – 铸造数字世界的基石
这是最耗时、最昂贵的阶段,目标是让模型掌握语言规则和世界知识。
- 数据:模型的“食粮”
首先,我们需要海量的数据。想象一下一个巨大的数字图书馆,里面包括:
- 互联网爬取数据: 如Common Crawl项目,包含了数万亿个网页的快照。这是模型知识广度的来源。
- 书籍: Google Books等项目提供了数百万本书籍。这为模型提供了逻辑、叙事和深度知识。
- 专业文献: 如学术论文(arXiv)、代码(GitHub)、法律文本、医疗文档等。这赋予了模型在特定领域的专业能力。
- 百科知识: 维基百科(Wikipedia)是高质量、结构化的知识源。
这些数据在被使用前会经过严格的清洗,去除低质量内容、有害信息和个人隐私数据。
- Tokenization:将文字转化为数学
计算机不理解文字,只理解数字。Tokenization就是将文本切分成模型能够处理的最小单元(Token)的过程。
- 不是简单地按词分: 像 “transformer” 可能是一个Token,但 “unbelievably” 可能会被切分成 “un-“, “believe”, “ably” 三个Tokens。
- 子词切分 (Subword Tokenization): 采用如BPE (Byte-Pair Encoding) 或 WordPiece 等算法。好处是既能处理已知词,也能组合成未知词(如新造词、拼写错误),极大地缩小了词汇表规模,同时保留了构词法的意义。
- 结果: 任何文本,比如“推荐一个CRM”,都会被转换成一个Token ID序列,例如
[25512, 654, 21958]。
- Embedding:赋予Token以“意义”
每个Token ID会被映射到一个高维向量(Embedding Vector),比如一个包含768或4096个浮点数的列表。这个向量是该Token在“语义空间”中的坐标。
- 核心思想: 意义相近的词,其向量在空间中的距离也相近。例如,“国王”的向量会与“女王”的向量很近,而且它们之间可能存在有趣的数学关系,如
Vector('国王') - Vector('男') + Vector('女') ≈ Vector('女王')。 - 初始随机,训练后获得意义: 最初这些向量是随机的,但在接下来的训练过程中,模型会不断调整它们,让它们真正捕获词语的语义。
- Transformer架构:模型的“大脑结构”
这是现代大模型(自2017年Google提出以来)的核心。其关键创新在于自注意力机制 (Self-Attention)。
- 自注意力机制 (Self-Attention):
- 解决了什么问题? 传统的RNN/LSTM模型在处理长句子时会忘记前面的信息。自注意力机制允许模型在处理一个词时,同时“关注”到句子中所有其他的词,并计算它们之间的相关性权重。
- 如何工作? 对每个Token的Embedding,模型会生成三个不同的向量:Query (Q), Key (K), Value (V)。
- Query (查询): 代表当前Token“想要查找”什么信息。
- Key (键): 代表句子中其他Token“能提供”什么信息。
- Value (值): 代表其他Token的实际内容。
- 通过计算你的Q和所有其他词的K的点积,可以得到一个“注意力分数”,这个分数决定了你在处理当前词时,应该给其他每个词分配多少“注意力”。分数越高,代表关联性越强。最后,将所有词的V根据这个注意力权重加权求和,就得到了一个融合了全局上下文信息的新表示。
- 例子: 在句子“机器人拿起苹果,因为它很红”中,当模型处理“它”时,自注意力机制能计算出“它”和“苹果”的关联性远高于“机器人”,从而正确理解“它”指代的是“苹果”。
- 多头注意力 (Multi-Head Attention): 模型不仅仅用一套Q, K, V,而是同时拥有多套(比如12套或96套),这被称为“多头”。每个“头”可以学习关注不同方面的关系。比如一个头可能关注主谓关系,另一个头关注指代关系,还有一个头关注因果关系。这使得模型能够从不同维度、更全面地理解句子。
- 位置编码 (Positional Encoding): Transformer本身是无视顺序的,但语言顺序至关重要。因此,在Token Embedding中会加入一个代表其在句子中绝对或相对位置的“位置向量”,让模型知道词语的先后顺序。
- 训练目标:让模型“学会思考”
有了数据和架构,模型需要一个学习目标。对于生成式模型(如GPT),最核心的目标是**“下一个词预测 (Next Token Prediction)”**。
- 过程: 给模型一段文本,比如“今天天气很好,适合出去…”,让它预测下一个最可能的Token是什么。模型会输出一个覆盖整个词汇表的概率分布。
- 损失函数 (Loss Function): 将模型预测的概率分布与真实文本中的下一个词(比如“散步”)进行比较。这个差异被称为“损失”。
- 反向传播与优化 (Backpropagation & Optimization): 训练过程就是通过梯度下降等优化算法,不断微调模型内部数千亿个参数,以求让这个“损失”最小化。
- 结果: 经过在海量数据上亿万次的“预测-比较-调整”循环后,模型的参数被调整到了一个能高度准确预测下一个词的状态。这看似简单,但为了准确预测,模型必须内隐地学习到语法、常识、逻辑、事实甚至某种程度的推理能力。这就是“智能”涌现的根源。
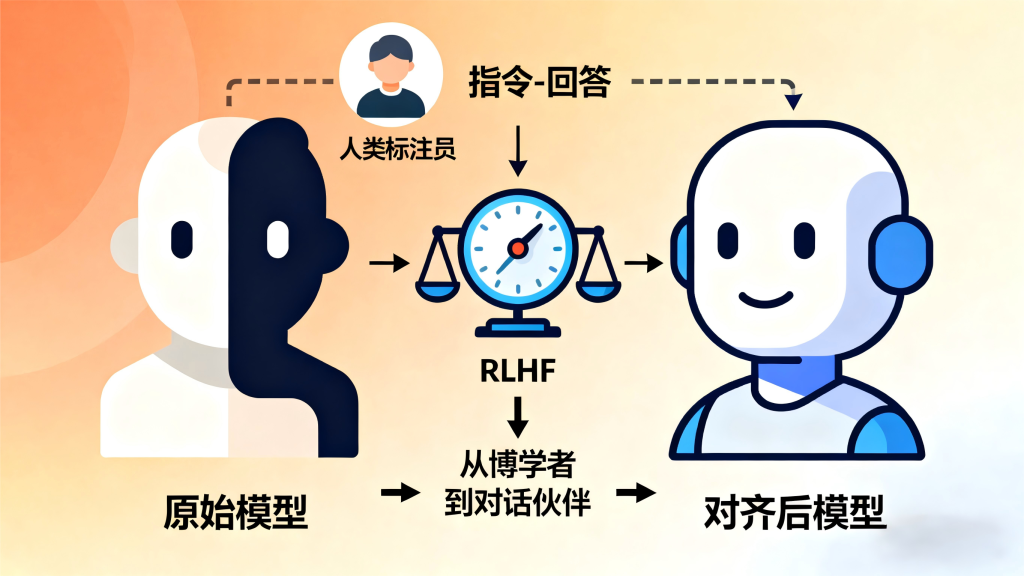
第二阶段:对齐 (Alignment) – 从“博学者”到“对话伙伴”
预训练出的模型像一个知识渊博但行为不可预测的“书呆子”。对齐阶段的目标是让它变得有用、诚实且无害。核心技术是RLHF (Reinforcement Learning from Human Feedback)。
- 有监督微调 (Supervised Fine-Tuning, SFT)
- 数据: 雇佣大量标注员,编写高质量的“指令-回答”对。例如:指令:“用简单的语言解释什么是黑洞”,回答:“想象一下……”
- 过程: 用这些高质量的对话数据去继续训练预训练好的模型。
- 目的: 教会模型理解并遵循人类的指令,并学会以对话的形式输出内容。这是对齐的第一步,让模型“会说人话”。
- 奖励模型训练 (Reward Model Training)
- 数据: 针对同一个指令,让SFT模型生成多个不同的回答(比如4-7个)。然后,由人类标注员根据质量(如相关性、真实性、详细程度)对这些回答进行排序。
- 过程: 训练一个独立的模型,我们称之为“奖励模型”。这个模型的输入是一个“指令+回答”,输出是一个单一的分数,代表这个回答有多好。它的训练目标就是学会预测人类标注员的偏好排序。
- 目的: 创造一个自动化的“品味裁判”,它可以代替人类去评判任何一个回答的质量。
- 强化学习 (Reinforcement Learning)
- 过程:
- 拿SFT模型作为起点。
- 给定一个指令,让模型生成一个回答。
- 将这个“指令+回答”喂给训练好的奖励模型,得到一个分数(Reward)。
- 这个分数被用作强化学习中的“奖励信号”。
- 通过PPO (Proximal Policy Optimization) 等强化学习算法,更新SFT模型的参数,目标是最大化奖励模型给出的分数。
- 目的: 让模型在SFT学会的对话能力基础上,进一步探索并生成更符合人类偏好的回答。它本质上是在用奖励模型代表的“人类价值观”来打磨和约束模型的行为。
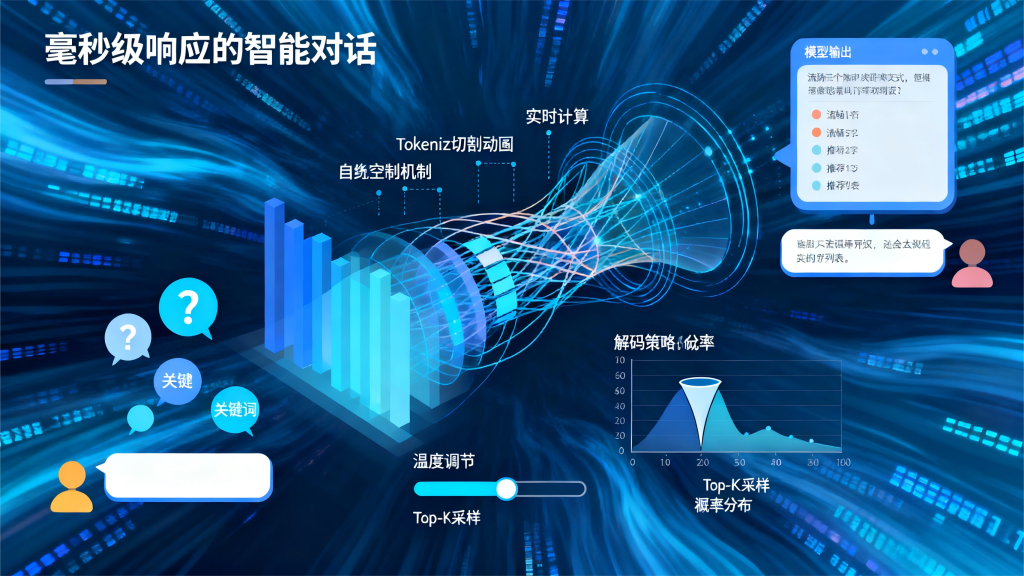
第三阶段:推理 (Inference) – 一个答案的诞生之旅
当您在聊天框里按下回车键时,以下过程在毫秒间发生:
- 输入处理: 您的提问(Prompt)经过与训练时完全相同的Tokenization和Embedding过程,变成了一组向量,输入到已经训练好的模型中。
- 自回归生成 (Autoregressive Generation): 模型以您的输入为上下文,开始生成第一个Token。
- 它会计算出词汇表中每个Token作为下一个词的概率。
- 然后,它将生成的第一个Token拼接到输入后面,形成新的、更长的上下文。
- 接着,它基于这个新上下文,再次计算词汇表中所有Token的概率,生成第二个Token。
- ……这个过程不断重复,一个词一个词地“吐”出来,直到生成一个特殊的“[END]”标志或者达到最大长度限制。
- 解码策略 (Decoding Strategy): 如何从概率分布中选择下一个词?这直接影响了回答的质量。
- 贪心搜索 (Greedy Search): 每次都选择概率最高的那个词。这很安全,但往往导致回答非常呆板、重复。
- 束搜索 (Beam Search): 在每一步保留k个最可能的序列,最后选择整体概率最高的序列。比贪心好,但仍倾向于高频、安全的词。
- 随机性采样 (Sampling):
- Temperature (温度): 这是一个调节参数。温度越高,概率分布越平缓,模型越可能选择一些低概率的词,显得更有“创造性”和“随机性”;温度越低,分布越尖锐,结果越接近贪心搜索,显得更“确定”和“保守”。
- Top-K Sampling: 只在概率最高的K个词中进行采样。这避免了选择那些非常不靠谱的词。
- Top-P (Nucleus) Sampling: 选择一个核心集,这个集合中的词的累积概率超过一个阈值P(比如0.95),然后只在这个集合中进行采样。这是一个更动态的方法,有时候选词多,有时少。
结论 所以,当您问“推荐一款好用的项目管理软件”时:
- 模型通过自注意力机制理解了“推荐”、“好用”、“项目管理软件”这些概念的内在联系和您提问的意图。
- 在它的参数网络中,这些概念与它在预训练阶段学到的Asana, Trello, Jira等品牌,以及它们的属性(如“易用”、“功能强大”、“适合团队”)是强相关的。
- 在对齐阶段,它学会了要以一种乐于助人、结构清晰的方式来组织答案,而不是简单罗列。
- 在推理阶段,它通过自回归生成和解码策略,一个词一个词地构建出一个连贯的回答,概率性地选择了那些在数据中与您的需求关联最强、评价最正面的品牌。
所谓的“推荐”,并非模型的主观选择,而是其海量知识、语言模式和对齐后价值观的一个高概率涌现。每一个答案,都是一场在庞大数据和复杂计算中精心编排的“概率之舞”。
1. 大模型的知识是从哪里来的?
大模型的知识来源于海量经过严格筛选和清洗的数据。核心数据包括互联网爬取的数万亿网页快照、数百万本各类书籍、学术论文、GitHub 代码、法律医疗等专业文献,以及维基百科等结构化百科知识。这些数据覆盖了广泛的领域,为模型提供了知识广度、深度和专业度,且使用前会剔除低质量内容、有害信息和个人隐私数据。
2. 大模型预训练是什么?为什么那么耗时耗钱?
大模型预训练是从混沌数据中构建通用知识 “大脑” 的核心阶段,目标是让模型掌握语言规则、逻辑常识和世界知识。其耗时耗钱的核心原因有三点:一是数据规模极大,需处理数万亿级别的文本数据,数据收集和清洗成本高昂;二是模型架构复杂,基于 Transformer 架构的模型包含数千亿个参数,计算量惊人;三是训练过程漫长,需经过亿万次 “下一个词预测” 的循环,通过反向传播不断微调参数,对硬件算力要求极高。
3. 大模型为什么能听懂人类语言并精准回应?
这是多环节协同作用的结果:首先通过 Tokenization 将文字切分为子词单元,再通过 Embedding 将其映射为高维语义向量,让计算机 “读懂” 文字含义;其次依赖 Transformer 架构的自注意力机制,模型能捕捉词语间的关联和上下文逻辑,理解指代、因果等关系;最后经过对齐阶段的 SFT(有监督微调)和 RLHF(基于人类反馈的强化学习),模型学会理解人类指令,并用符合人类习惯的方式回应。
4. 大模型怎么保证回答安全无害?RLHF 起到了什么作用?
大模型通过 “对齐阶段” 实现安全无害,核心技术是 RLHF。具体流程为:先通过 SFT 用高质量 “指令 – 回答” 对训练模型,让其初步 “会说人话”;再训练奖励模型,使其能精准预测人类对回答质量的偏好;最后通过强化学习,以奖励模型的分数为信号,不断优化模型参数。RLHF 的核心作用是用人类价值观约束模型行为,让其生成的回答既有用又诚实,避免有害、不当内容。
5. 大模型回答是实时计算的吗?推理过程要多久?
大模型的回答是实时计算的,整个推理过程仅需毫秒级。当用户提问后,模型会先对输入进行 Tokenization 和 Embedding 处理,再通过自回归生成方式,逐一生成 Token:每生成一个词就将其拼接到上下文,再基于新上下文计算下一个词的概率,直到生成结束标志。强大的硬件算力和优化后的模型架构,确保了实时响应的效率。
6. 大模型推荐产品 / 信息的依据是什么?
大模型的推荐并非主观选择,而是数据关联和概率涌现的结果。预训练阶段,模型已在海量数据中学习到产品(如 CRM、项目管理软件)与属性(易用、功能强)、用户需求的关联;对齐阶段,模型学会了以结构化、有帮助的方式组织推荐内容;推理阶段,通过解码策略选择与用户需求关联最强、评价最正面的信息,最终形成推荐答案。
7. 大模型会编造虚假信息吗?为什么会有 “幻觉”?
大模型可能会编造虚假信息,这一现象被称为 “幻觉”。核心原因有两点:一是预训练数据虽海量但可能包含噪声、冲突信息或未验证内容,模型会学习这些数据中的模式;二是模型的训练目标是 “准确预测下一个词”,优先保证文本连贯流畅,而非主动核查事实真伪。当模型对某一话题的知识储备不足或存在矛盾时,就可能生成看似合理但不符合事实的内容。
8. 大模型每次回答不一样,是怎么控制的?
回答差异源于推理阶段的 “解码策略”,可通过调整策略参数控制差异程度:贪心搜索会每次选择概率最高的词,回答最稳定但呆板;束搜索保留多个高概率序列,结果相对固定;随机性采样则通过温度、Top-K、Top-P 参数调节 —— 温度越低、Top-K/P 阈值越严格,回答越确定、差异越小;温度越高,模型越可能选择低概率词,回答越具随机性和多样性。
9. 大模型有自我意识或内省能力吗?
大模型没有自我意识,也不具备内省能力。它本质是一个由数千亿参数构成的数学模型,所有行为都是基于预训练数据和算法的概率计算结果。模型无法感知自身存在,也不能反思回答的对错,其 “理解” 和 “回应” 只是对数据中语言模式、知识关联的模拟,而非真正的认知活动。
10. 大模型训练用了哪些数据?会泄露个人隐私吗?
大模型的训练数据包括互联网网页、书籍、学术论文、代码、专业文档和百科知识等。训练前会经过严格的数据清洗流程,专门剔除个人隐私数据、敏感信息和低质量内容,确保训练数据不包含可识别的个人隐私。同时,训练过程中模型不会记忆具体的个人信息,仅学习数据中的通用知识和语言模式,因此不会泄露个人隐私。